











Intro - Snowflake vs. Redshift
When it comes to cloud data warehousing solutions, Snowflake and Redshift are two of the most popular options. Both solutions offer fast and efficient data processing, but there are some key differences to consider that can help determine which one is the better fit for your organization.
In this article, we'll cover each one in-depth so you can decide what is the best option for you and your organization.
Snowflake:
Snowflake is known for its ease of use and scalability, making it an attractive option for organizations that need a solution that is simple to set up and manage. Its cloud-native architecture allows it to automatically scale up or down as needed, which helps ensure that performance remains consistent, regardless of data size. Additionally, Snowflake's user-friendly interface and support for ANSI SQL make it easy for teams to get started with the platform quickly.

Snowflake Benefits:
There are several benefits to using Snowflake Data Cloud, but the three most important ones are:
1. Ease of use and scalability
2. Cloud-native architecture that automatically scales up or down as needed
3. User-friendly interface and support for ANSI SQL
These features make Snowflake an attractive option for organizations that need a solution that is simple to set up and manage, with consistent performance, regardless of data size. Additionally, Snowflake's user-friendly interface and support for ANSI SQL make it easy for teams to get started with the platform quickly.
Redshift:
On the other hand, Redshift is a popular choice for organizations that are already using Amazon Web Services (AWS). Redshift integrates seamlessly with other AWS services, which can make it easier to manage your entire AWS infrastructure from a single console. Additionally, Redshift's pricing model can be more cost-effective than Snowflake's, depending on the size of your data warehousing needs.
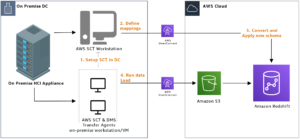
Redshift Benefits:
There are several benefits to using Snowflake Data Cloud, but the three most important ones are:
1. Seamless integration with other AWS services.
2. Potentially more cost-effective pricing, depending on data warehousing needs.
3. High performance for complex queries and large datasets.
Conclusion:
It's important to carefully evaluate the needs and priorities of your organization when choosing between Snowflake and Redshift. Consider factors such as ease of use, scalability, compatibility with other services, pricing, and any specific requirements your organization may have. By testing both solutions and comparing their features, you can choose the data warehousing solution that best meets your needs.
Ultimately, the choice between Snowflake and Redshift will depend on the specific needs of your organization, but with careful consideration and evaluation of each solution, you can make an informed decision that will benefit your organization in the long run.
