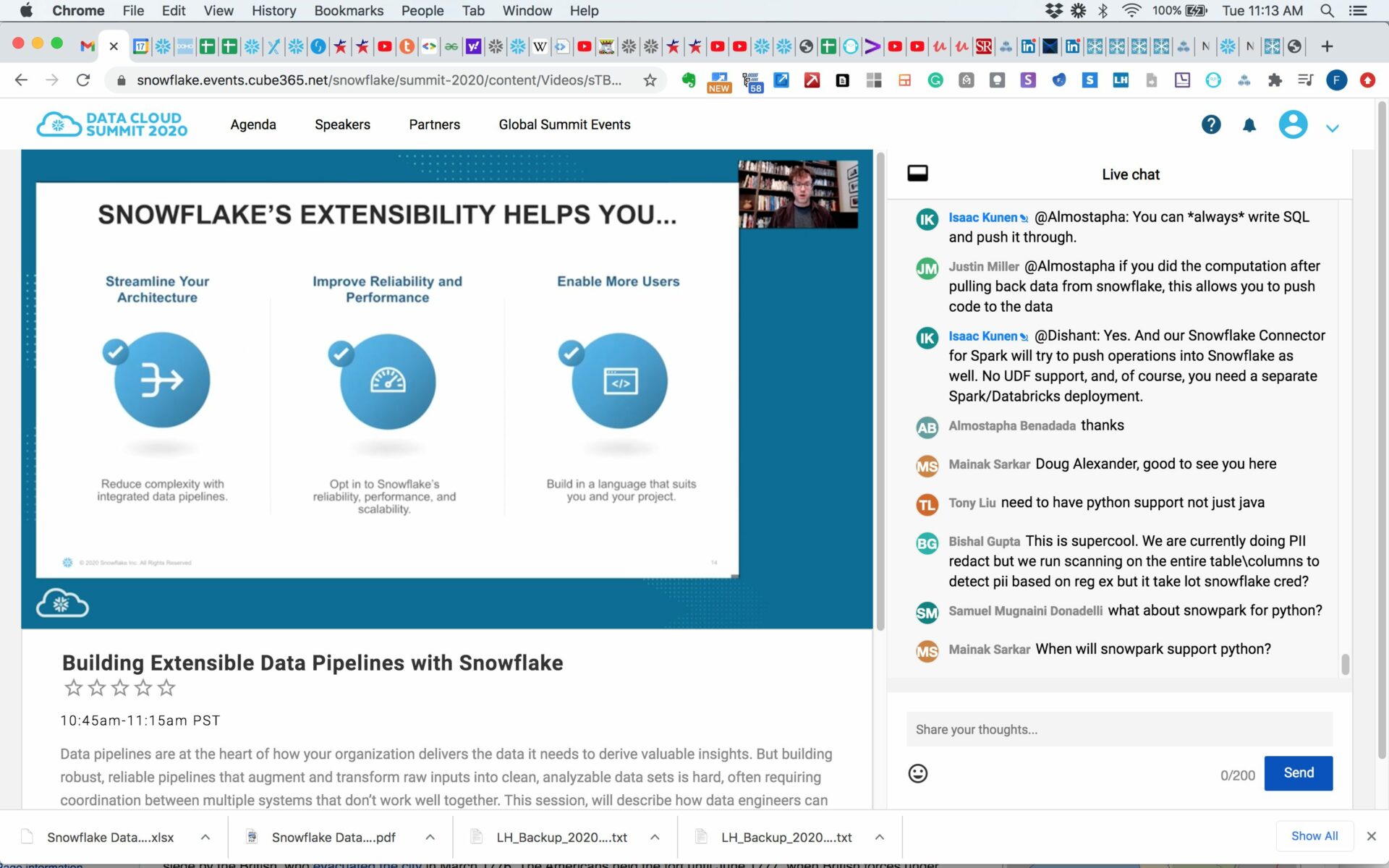
Data pipelines are at the heart of how your organization delivers the data it needs to derive valuable insights. But building robust, reliable pipelines that augment and transform raw inputs into clean, analyzable data sets is hard, often requiring coordination between multiple systems that don’t work well together. This session, will describe how data engineers can use Snowflake’s extensibility features to build simple pipelines that incorporate code and libraries written in a variety of languages, and integrate naturally with third-party services. Snowflake representatives will build a real-life demo using some of its latest features, including external functions, Java UDFs, and more.