











Data Warehousing has been around for quite a few years. The last 20 years it has made the greatest impact on businesses. With the recent exponential growth in customer and sensor data then its been challenging for traditional data warehouses and appliances because they just were not designed for that amount of data. The cloud data warehouse has evolved to solve that and enable businesses to be more data-driven.
Our big data practice has always sought to find the best solutions for our customers and we have had to evolve as the data collection and the data warehouse has evolved over the last 20 years. We have gone from RDBMS (Oracle, SQL Server, MySQL) solutions to Appliance (Teradata, Netezza, Vertica) to Hadoop (HDFS/Hive, etc.) to Cloud (Redshift, Azure, BigQuery) to finally now.... A fully Elastic Cloud Data Warehouse that was designed from the ground up to leverage the cloud's scalability (Snowflake). It's been an interesting journey with many twists and turns but I'm the most excited as I've ever been. Here is how the Data Warehouse evolved beyond the initial fun days of Bill Inmon and Ralph Kimball. (Yes, I still have all those books - The Data Warehouse Toolkit, The Data Webhouse Toolkit, etc. Good times.)
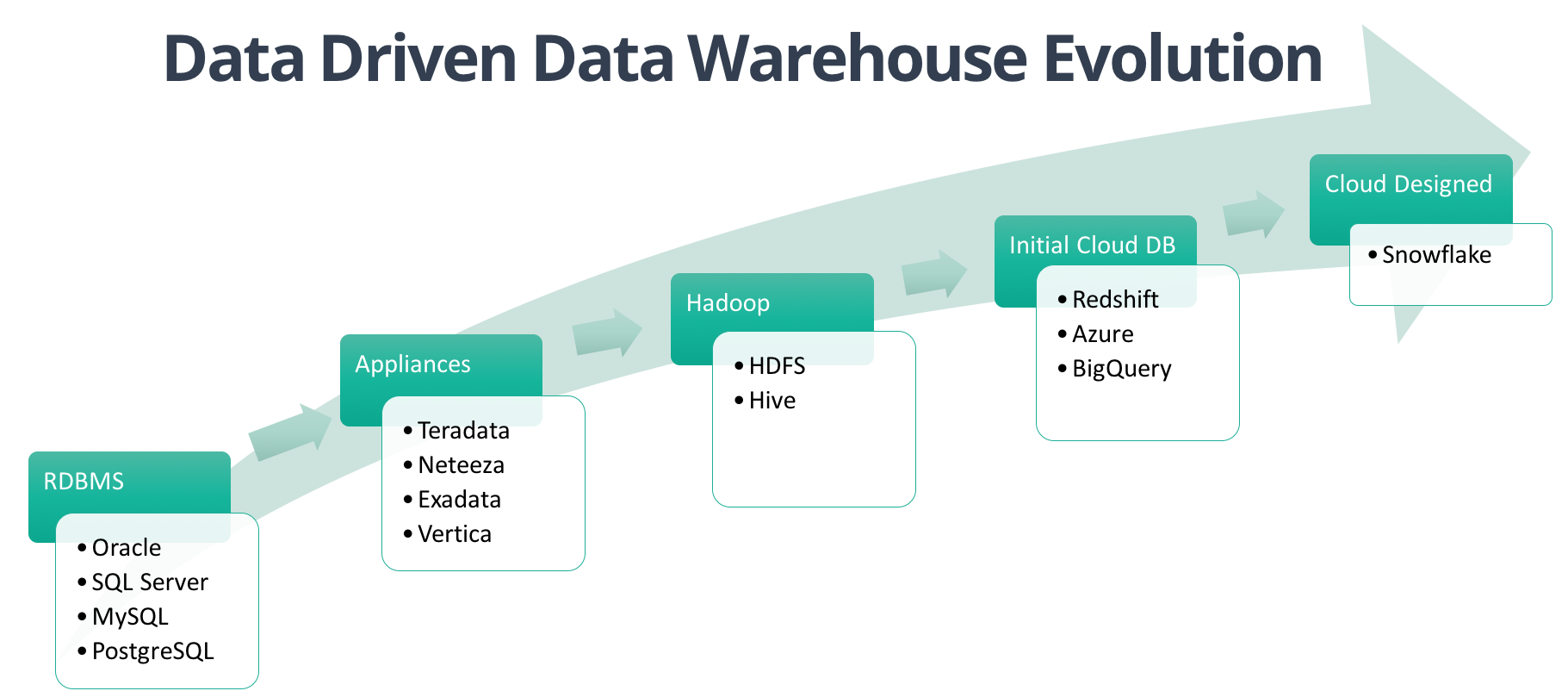
Stage 1 – Regular RDBMS
Relational Database Management Systems set the first major foundation for effective Data Warehousing. Oracle Server, IBM DB2, Microsoft SQL, MySQL, PostgreSQL and so on, are all relational database management systems we used to build traditional data warehouses with fact tables and dimension tables. These worked fine in the 1990s and even early 2000s for many traditional companies before consumer and operational data began to grow in larger volumes. This was the era of traditional batch jobs from various data sources that would be loaded in an Extraction, Transformation, and Load (ETL) process.
Problems started surfacing when response times went down against large target databases. The other traditional problem was there was contention between the data loading and the data usage where users couldn't use the data warehouse effectively while it was being loaded. In order to keep up with growing requirements, it became vital to employ advanced features like parallelism, indexing, aggregate processing, etc. This only added to the complexity of maintaining huge databases, whilst failing to marginally improve the throughput. In order to tackle all such problems, technologists started designing appliance type systems that could handle the exponential growth in data that started to happen in the 2000s.
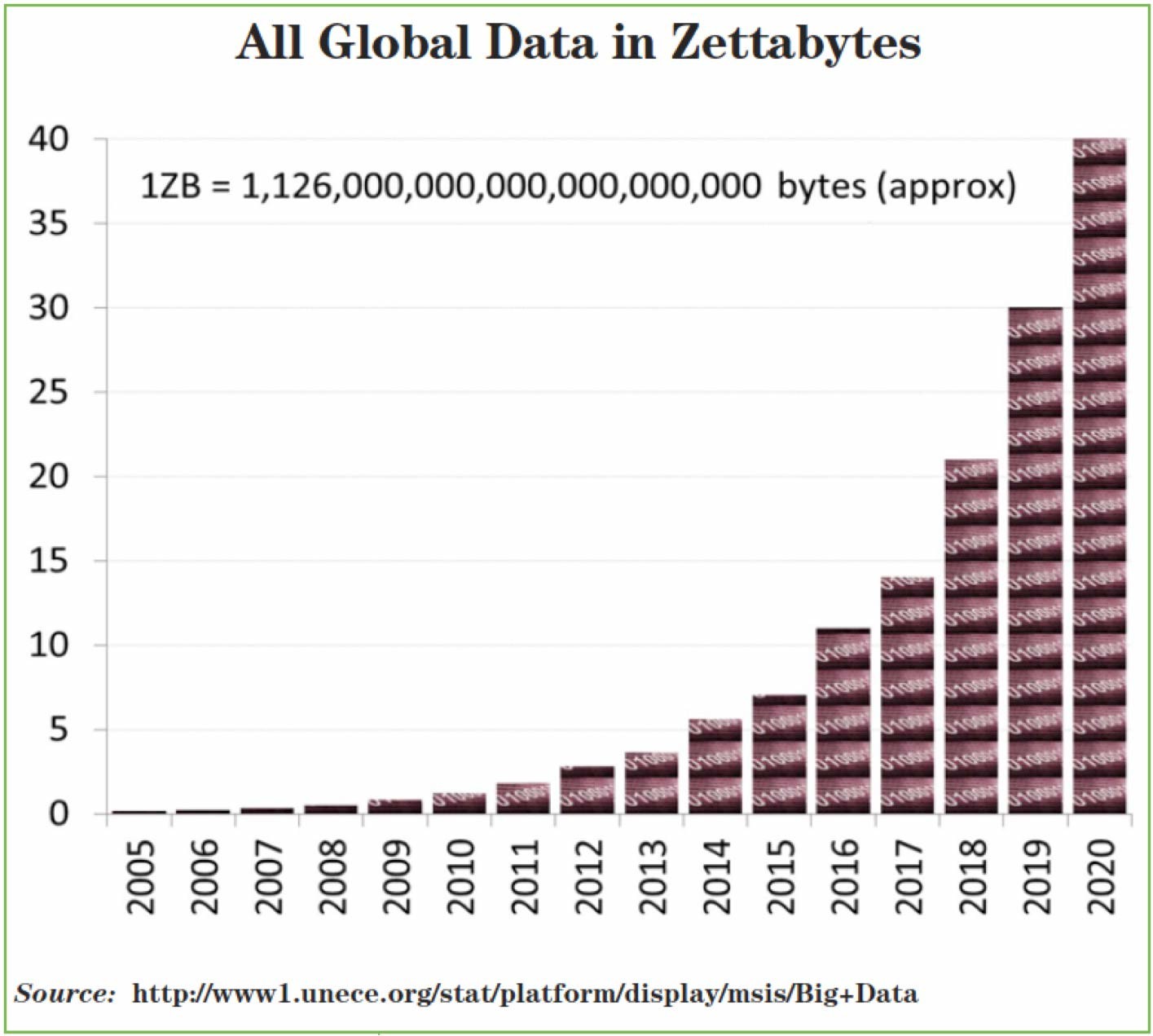
Data Growth....or really Data Explosive Growth.
Stage 2 – Analytics Appliances and In-Memory Databases - 2000
When we first introduced clients to databases like Teradata it was the next evolution. It was amazingly fast using Massively Parallel Processing (MPP) architecture. In-memory databases also brought the promise of quick results as operations would be performed on the system’s main memory. This did bring a revolutionary change in the world of Data Warehousing, but it also brought a huge financial overhead and really could be only used by larger companies with large enough budgets to afford both the costs of the appliances and the engineers/consultants to maintain them.
In-memory databases and associated analytics applications brought huge advantages to the table for companies with larger amounts of data. The solutions though still had to be designed very carefully, and any room for scalability only meant a higher cost. Also, there is no elasticity at all with these solutions so you have to budget and design for the largest queries which means businesses pay for idle compute power all the time. Also, when they come to the point where they have to upgrade it's a painful and costly process.
Stage 3 – Hadoop HDFS/Hive - 2005
Released in 2005, Hadoop really set-off a storm in the Data Analytics world. It was the first major platform developed for Big Data operations, and most of all it was Open Source. Hadoop was widely accepted and still is, with many people seeing it as an extension to the data warehouse architecture that reduces the traditional scaling limitations usually brought by relational database management systems. But while Hadoop brought advantages such as unlimited scaling it came with the disadvantages of a steep learning curve and a lot of cost to architect and hire additional staff to create the solution. Regular businesses with traditional RDBMS data warehouses or data appliances have to hire or train to build entirely new skills. Hadoop is an entire ecosystem on its own and it's typically just too costly and complex for most businesses so we could only deploy this solution at certain types of clients.
Stage 4 - Redshift, Google Big Query, Azure Data Warehousing - 2012
The next major Big Data and Data Warehouse evolution was the movement to the cloud like almost all technical applications. Right about the time Data Mining and Analytics were becoming a hit in all commercial sectors, Cloud Computing was also becoming a norm. In order to bring the benefits of Cloud to compute-intensive applications such as Data Warehousing, Amazon released Redshift, a data warehousing service. Redshift brought with it a plethora of features and the ability to deploy clusters and get closer to a semi-elastic data warehouse. Redshift is built on top of technology from ParAccel and is based on PostgreSQL 8.0.2. PostgreSQL 8.0.2 was released in 2005. Google BigQuery was introduced around the same time also and Microsoft created a Data Warehouse version of SQL Server in the cloud as well. These initial cloud solutions by the big 3 cloud providers was another advantage for many clients but each of these solutions has limitations and while optimized for the cloud they are all based on previous technologies of each of these companies. None of them were designed for the cloud from the ground up.
Stage 5 – Snowflake - 2016. SQL Data Warehouse designed for the Cloud. DWaaS.
We’ve all heard of SaaS, PaaS and IaaS, but rarely does the word DWaaS (Data Warehouse as a Service). That’s what Snowflake is all about. For all the other previous stages of the evolution of data warehousing there has been a ton of maintenance to take care of which adds up to tons of costs for maintenance for businesses. All the other solutions were relatively inelastic as well.
Snowflake, like Redshift, is a Cloud-Based Data Warehousing Service, only with more advantages, minus the limitations. Like the other cloud solutions, there is no software to install and no servers to maintain. First and foremost, Snowflake possesses the ability to scale itself to multiples of petabytes, performing operations up to 200 times faster than conventional data warehousing solutions. The latter can be achieved through separate warehouses, with one serving analytical workloads and the other serving ETL ones. Additional warehouses can be started up in seconds compared to other on-prem or cloud solutions that take hours to copy over all the data.
Snowflake’s separation of compute and storage architecture means you pay only for what you use. You can scale up and down Snowflake workloads in seconds. This brings the true power of Elastic Cloud scaling to your company’s doorstep for any sized company. However, a true game changer from Snowflake’s part is the way in which it stores data. Snowflake's architecture uses metadata “copy-on-write” clones that can be created in seconds for QA or Staging testing. This eliminates the need for extra space and time for copying data over. This is a feature that’s highly unique to Snowflake and not found in any other solutions. This clone copy functionality along with the time travel features allow you to run Snowflake without having to deal with the maintenance and costs of backups. All the backup is done for you with the service.
This last evolution with Snowflake has been truly disruptive for companies because it has lowered the Total Cost of Ownership (TCO) so dramatically and made it so much easier to access and actually use your data.
So the latest evolution is here and we are really excited about it because of:
- Dramatic reduction of TCO.
- Creating a clone of a database takes seconds due to the metadata architecture.
- Security is now taken care of for you.
- No contention issues to deal with. ETL can operate in a separate warehouse from Data Scientists, Marketing, Finance, etc.
- Paying only for what you use. No large up front costs.
- The ability to mix semi structure JSON with relational data provides huge efficiencies
We hope that this overview has been helpful. If you want to learn more about Snowflake, be sure to check out our blog on a regular basis for more information.
